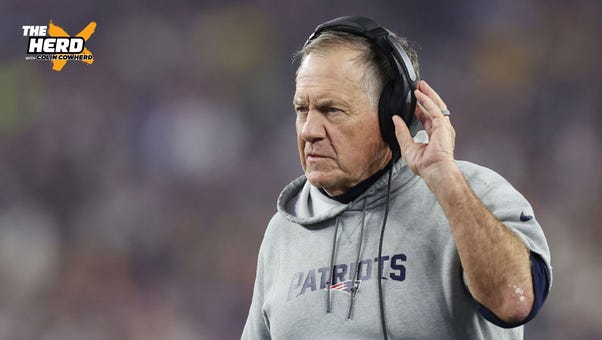my favs
Access and manage your favorites here
DISMISS
Home
Scores
Watch
Odds
Super 6
Stories
Search
Sign In
Account
SPORTS & TEAMS
PLAYERS
SHOWS
PERSONALITIES
SPORTS
SPORTS & TEAMS
PLAYERS
SHOWS
PERSONALITIES
SPORTS
NFL
NCAA FB
MLB
NBA
NCAA BK
NASCAR
Soccer
UFL
NCAAW BK
NHL
Golf
Premier Boxing Champions
WWE
UFC
WNBA
Tennis
Motor Sports
Professional Bowlers Association
Horse Racing
Westminster Kennel Club
FIBA
Olympics
World Baseball Classic
NRL
NBA
NBA
NBA
Atlanta Hawks
Boston Celtics
Brooklyn Nets
Charlotte Hornets
Chicago Bulls
Cleveland Cavaliers
Dallas Mavericks
Denver Nuggets
Detroit Pistons
Golden State Warriors
Houston Rockets
Indiana Pacers
LA Clippers
Los Angeles Lakers
Memphis Grizzlies
Miami Heat
Milwaukee Bucks
Minnesota Timberwolves
New Orleans Pelicans
New York Knicks
Oklahoma City Thunder
Orlando Magic
Philadelphia 76ers
Phoenix Suns
Portland Trail Blazers
Sacramento Kings
San Antonio Spurs
Toronto Raptors
Utah Jazz
Washington Wizards
NBA
PLAYOFFS: 2 GAMES today
PLAYOFFS: 2 GAMES today
NBA
>
NBA
FEATURED
FEATURED
SCORES
STANDINGS
SCHEDULE
STATS
PLAYOFF PICTURE
More
POWER RANKINGS
ODDS
VIDEOS
NEWS
PLAYER NEWS
INJURIES
TEAMS
SOCIAL
NBA DRAFT
EDITOR'S PICKS
MORE NBA NEWS
How Steve Kerr navigated his toughest season with Warriors: 'We love each other'
1 DAY AGO
•
FOX SPORTS
2024 NBA Power Rankings: Celtics, Nuggets rise back to the top
APRIL 8
•
FOX SPORTS
2023-24 NBA Rookie of the Year odds: Wembanyama becomes even bigger favorite
MARCH 18
•
FOX SPORTS
2024 NBA Western Conference odds: Nuggets favored to clinch No. 1 seed
5 DAYS AGO
•
FOX SPORTS
2023-24 NBA Most Improved odds: 76ers' Tyrese Maxey favored, Coby White rising
MARCH 18
•
FOX SPORTS
2024 NBA Play-In Tournament: Bracket, schedule, scores, standings, rules
13 HOURS AGO
•
FOX SPORTS
2024 NBA playoff bracket, picture: Updated Schedule, scores
13 HOURS AGO
•
FOX SPORTS
MORE NBA NEWS
ADVERTISEMENT
TRENDING VIDEOS
MORE NBA VIDEOS
Braves' Ronald Acuña Jr. hits first home run of the season vs. Astros
7 HOURS AGO
•
FOX SPORTS
Robert Kraft reportedly warned Arthur Blank not to trust Bill Belichick | The Herd
9 HOURS AGO
•
FOX SPORTS
Could Giants trade up for J.J. McCarthy? | The Herd
6 HOURS AGO
•
FOX SPORTS
Colin's NBA playoff predictions: OKC wins a series, Lakers advance, Knicks lose Round 1 | The Herd
1 DAY AGO
•
FOX SPORTS
Why Bill Belichick is portrayed as 'Dynasty's' antagonist | The Herd
MARCH 18
•
FOX SPORTS
Zion Williamson to miss play-in game vs. Kings | The Herd
8 HOURS AGO
•
FOX SPORTS
Should the Giants trade up for J.J McCarthy? | The Herd
8 HOURS AGO
•
FOX SPORTS
MORE NBA VIDEOS
FOLLOW THE NBA
Follow your favorites to personalize your FOX Sports experience
BETTING INSIGHTS
MORE NBA BETTING INSIGHTS
2024 NBA Championship odds: Celtics, Nuggets favored for Finals; Lakers surging
8 HOURS AGO
•
FOX SPORTS
2024 NBA Playoff odds: Play-in tournament, first-round odds tracker
9 HOURS AGO
•
FOX SPORTS
Pelicans star Zion Williamson reportedly ruled out of play-in Game vs. Kings
9 HOURS AGO
•
FOX SPORTS
MORE NBA BETTING INSIGHTS